Quick(ish) Price Check on a Car
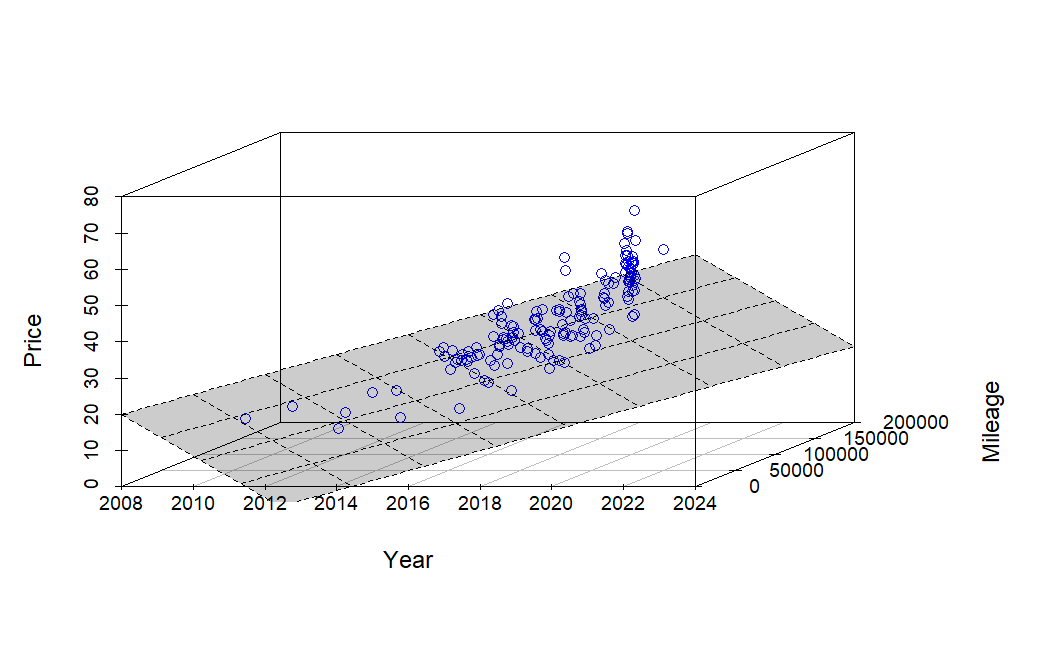
So, is it a good price? With my oldest daughter heading off to college soon, we’ve realized that our family car doesn’t need to be as large as it used to be. We’ve had a great relationship with our local CarMax over the years, and we appreciate their no-haggle pricing model. My wife had her … Read more