Ever wonder why fund managers can’t beat the S&P 500? ‘Cause they’re sheep — and the sheep get slaughtered. I been in the business since ’69. Most of these high paid MBAs from Harvard never make it. You need a system, discipline, good people, no deal junkies, no toreadores, the deal flow burns most people out by 35. Give me PSHs — poor, smart and hungry. And no feelings. You don’t win ’em all, you don’t love ’em all, you keep on fighting . . . and if you need a friend, get a dog . . . it’s trench warfare out there sport and in here too. — Gordon Gecko
I built a much better model with more realistic constraints available here
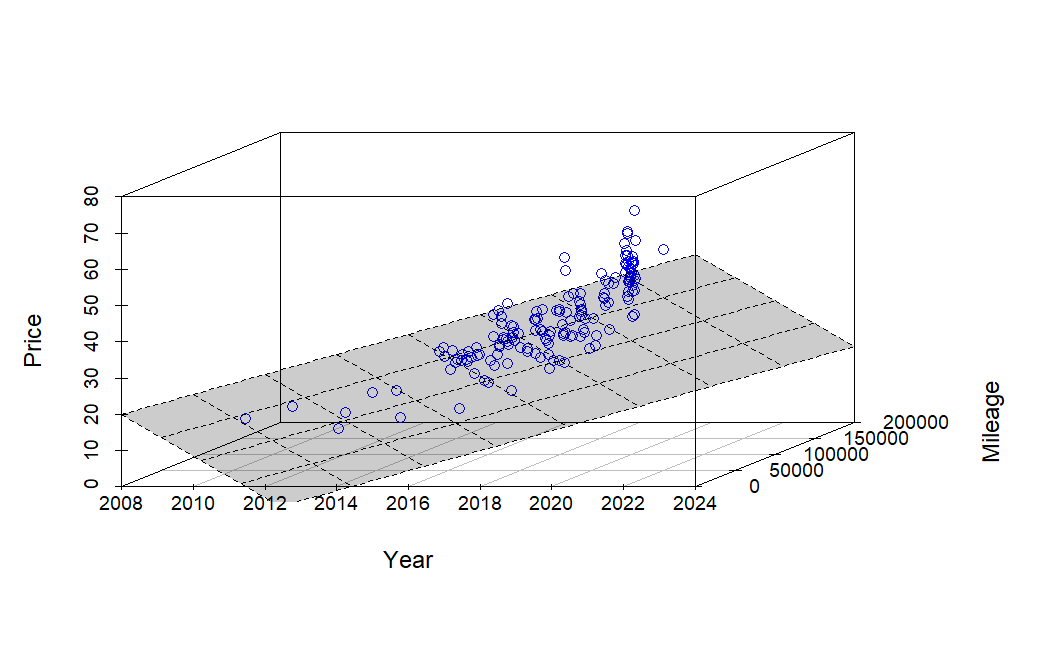
Outside of generating new information or product, risk, diversity and time horizon are only variables I’m convinced an investor can control. This means invest broadly over long time horizons and keep taxes and expenses low. If you want outsized returns, you must take on more risk or make something people want to buy. Most wealth is created by businesses making real products, but wealth can still accumulate from appreciating assets (real estate, land, gold, internet domain names, etc). However, both these methods take a lot of time and effort. Can you make a lot more quickly through selling VOIP services, posting internet ads and joining a Brazilian-focused multi-level marketing (MLM) club called TelexFree?
Read more